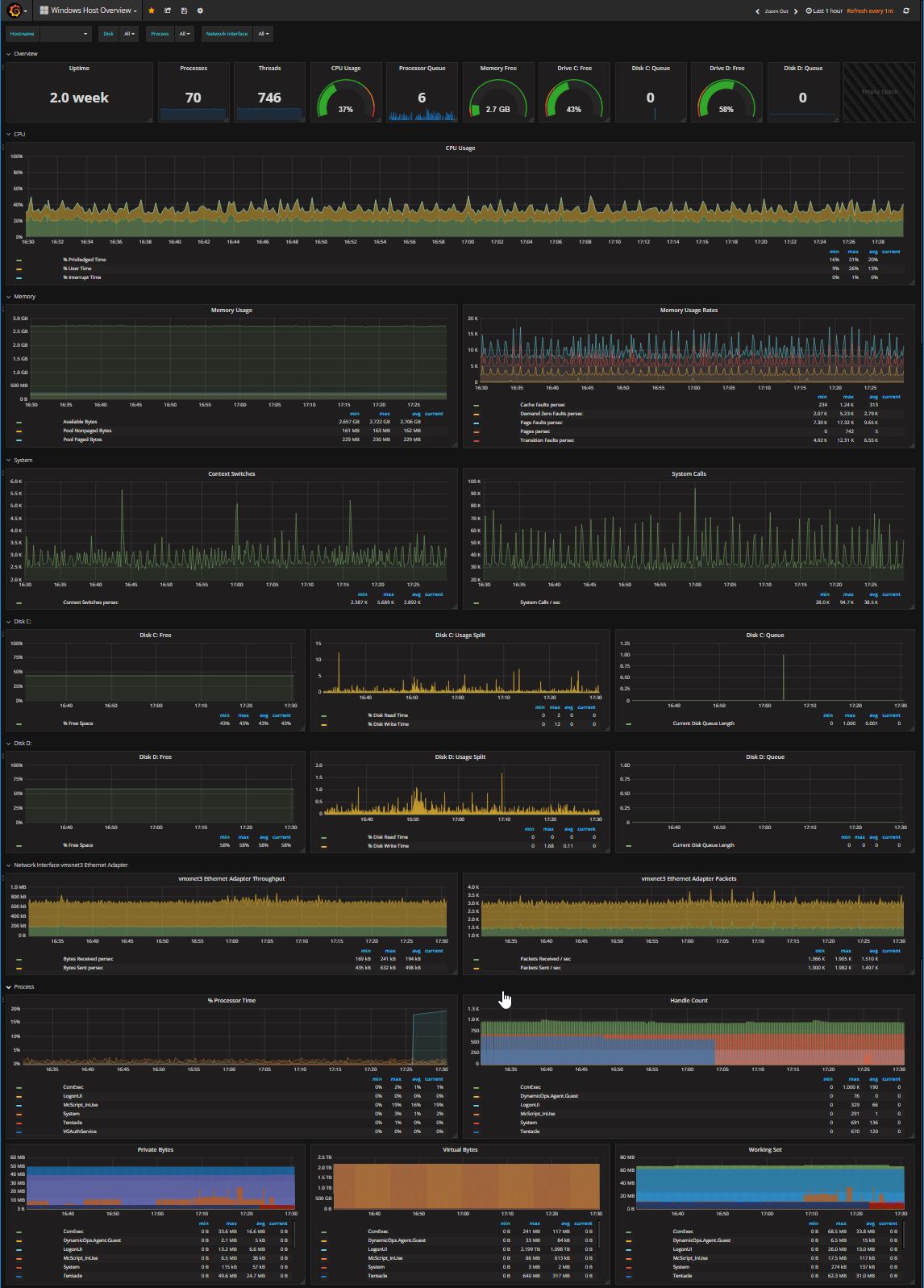
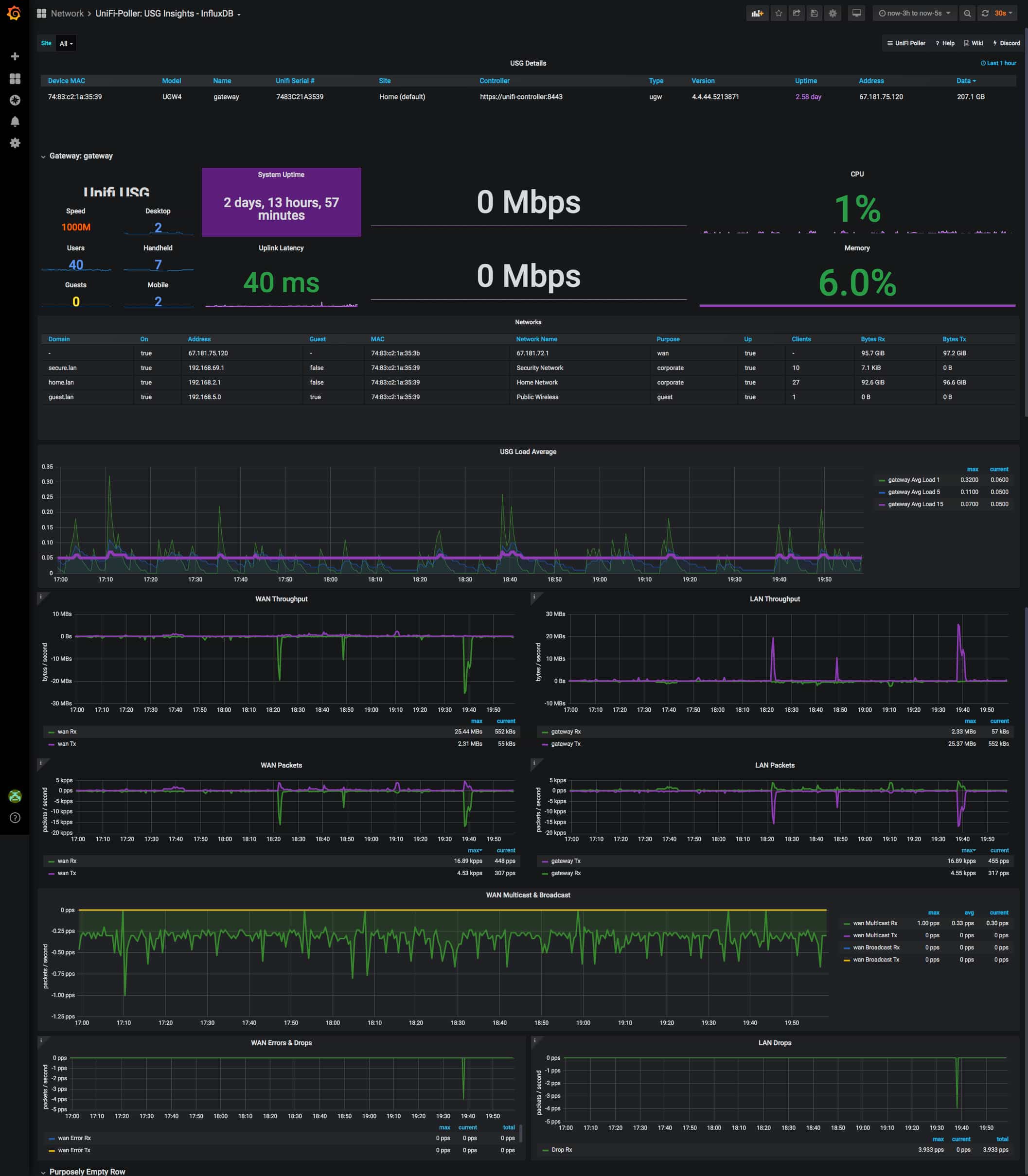
Category: Uncategorized
Weekly Unbound Updates on RaspberryPi
Information and configuration steps around setting up an automated Cron job to pool the root hints weekly and restart unbound after doing so.
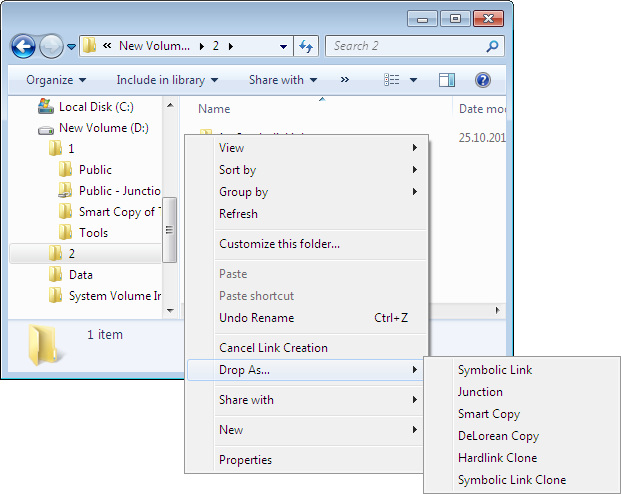
Symbolic Links on Windows 10
This is not meant as a tutorial in any way, I’m simply trying to not forget this as I need it about once every two years or so and always forget how to do it. The information was found here: https://superuser.com/questions/1020821/how-to-create-a-symbolic-link-on-windows-10 The option I went with was the PowerShell route suggested by Peter Hahndorf: Open […]
“What do you need?”, a life lesson; courtesy Amazon Web Services
“What do you need?” is an important thing to know. It allows you to more accurately predict what your costs might be for any longer term obligation. And to be obvious, this relates to pretty much everything, from how many miles you drive to derive fuel costs and a budget for them, to how much […]
Programmatic Paralysis Or a senior developer’s hobby problem
Over the course of my career, heck, over the course of my life, I’ve had a reoccurring, “issue” shall we say. In a nutshell, I feel like doing some programming, but what shall I write? You see, programming for me, since the age of nine, has been my hobby. I just happen to be one […]
Team: Work Gaming Clan
A gaming group, “Team: Work” has just blown into town. Not so much a competive gaming clan, but more of a group of folks who like to play online multi-player games of all styles and genres. The name comes from the concept that team based games require Team Work! Crazy concept I know. There is […]
The search has ended!
Well my friends, I have rejoined the ranks of the employed once again! A little spot called Insurance.com. I have to say I'm incredibly excited to start! The guys I interviewed with were awesome and I have a long time friend (26 years (whoa, I feel old lol 🙂 )) has been working there for […]