Grafana, Prometheus, and AdGuardHome DNS, using Docker.
Goal: To use my existing Grafana instance to visual data from AdguardHome DNS which uses a Prometheus database for metric storage and the AdguardExporter software application which scrapes the Adguard API and pushes the data to Prometheus.
InfluxDB Consumed Available Drive Space
A friend of mine and myself run some Grafana instances to monitor various things vi Telegraf. John was having some storage space issues on his machine and noticed that in our default installations, we had never set the data retention policies beyond default which keeps them forever!
Below is John Mora’s write-up of addressing the issue, Thank you sir!
I have used the process as documented and unsurprisingly it fixed my problem as well.
Weekly Unbound Updates on RaspberryPi
Information and configuration steps around setting up an automated Cron job to pool the root hints weekly and restart unbound after doing so.
Markdown Test
Markdown Markdown is a lightweight markup language with plain text formatting syntax. Its design allows it to be converted to many output formats, but the original tool by the same name only supports HTML. Markdown is often used to format readme files, for writing messages in online discussion forums, and to create rich text using […]
Getting my new old job
I just upgraded my blog a new version and found this old draft from October 19th 2011. I’m not sure why I never published it but I am now. It is not particularly interesting or inciting but enjoy my thoughts. This past Monday I started a new job, well sort-of new anyway. I find myself […]
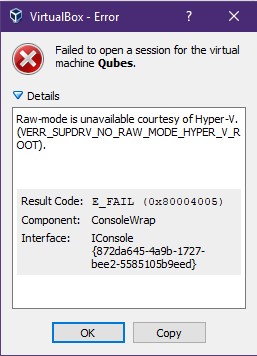
Disable Hyper-V under Windows 10
Trying to disable Hyper-V under Windows 10 is a little trickier than simply uninstalling it; but not much! tl;dr If you’re just interested in how to disable Hyper-V so VirtualBox can get RAW mode, skip down to the “Turning off Hyper-V” section below. Some background I am a fan of virtual machines but I don’t […]